How I refactored the decision making system of the CBS
The first version
The original decision-making flow in our system was a loan-origination pipeline, and I had built it the way most people build their first workflow: as a status machine. An order had a status field. The field said where the order currently was — pending_commission, commission_approved, pending_underwriter, underwriter_approved, and so on — and the code that read it knew, because of how it was written, what was supposed to happen next. The transitions lived inside a switch statement. Each new status I added meant a new branch.
For what it was, it worked well. It solved the problems I had at the time, and they were real problems. Anybody on the team could look at an order and know exactly where in the pipeline it was sitting. We could answer "who needs to take action on this?" by reading one field. The audit story was easy because every status change was a row in a history table, and the order of operations was implicit in the names. I could explain the whole thing on a whiteboard in five minutes. For our single financial product, with its single approval sequence, the status machine was honestly fine.
The things it was not solving became visible the moment the business asked for a second financial product. The second product needed a credit-bureau check before the human review, not after. It needed a manager approval that did not exist in the first product. One of the roles was renamed because compliance had decided the title meant something different. None of this was unreasonable — it was the most normal kind of business request — but my status machine could not absorb any of it cleanly, because the statuses were not abstract. They named specific roles in a specific order for a specific product. Every status was a hardcoded position in a hardcoded sequence. There was no way to reuse them across products, and there was no way to reorder them without renaming everything.
I spent two days trying to fix it the obvious way — adding product-prefixed statuses, branching the switch on product type, layering exceptions on top of exceptions. The code got worse linearly. I could feel I was patching the wrong layer, but I could not yet see where the right one was.
The night I started seeing a graph
The thing that flipped my thinking was, embarrassingly, just sitting still long enough. I was at home, not even at my laptop, and I realized that the status field had been quietly doing two jobs at once. It was telling me where the order currently was, which is a property of the order. And it was telling me where the order was going next, which is a property of the flow. Those are not the same fact, and when you fuse them into one field, every change to the flow forces a change to the field's type.
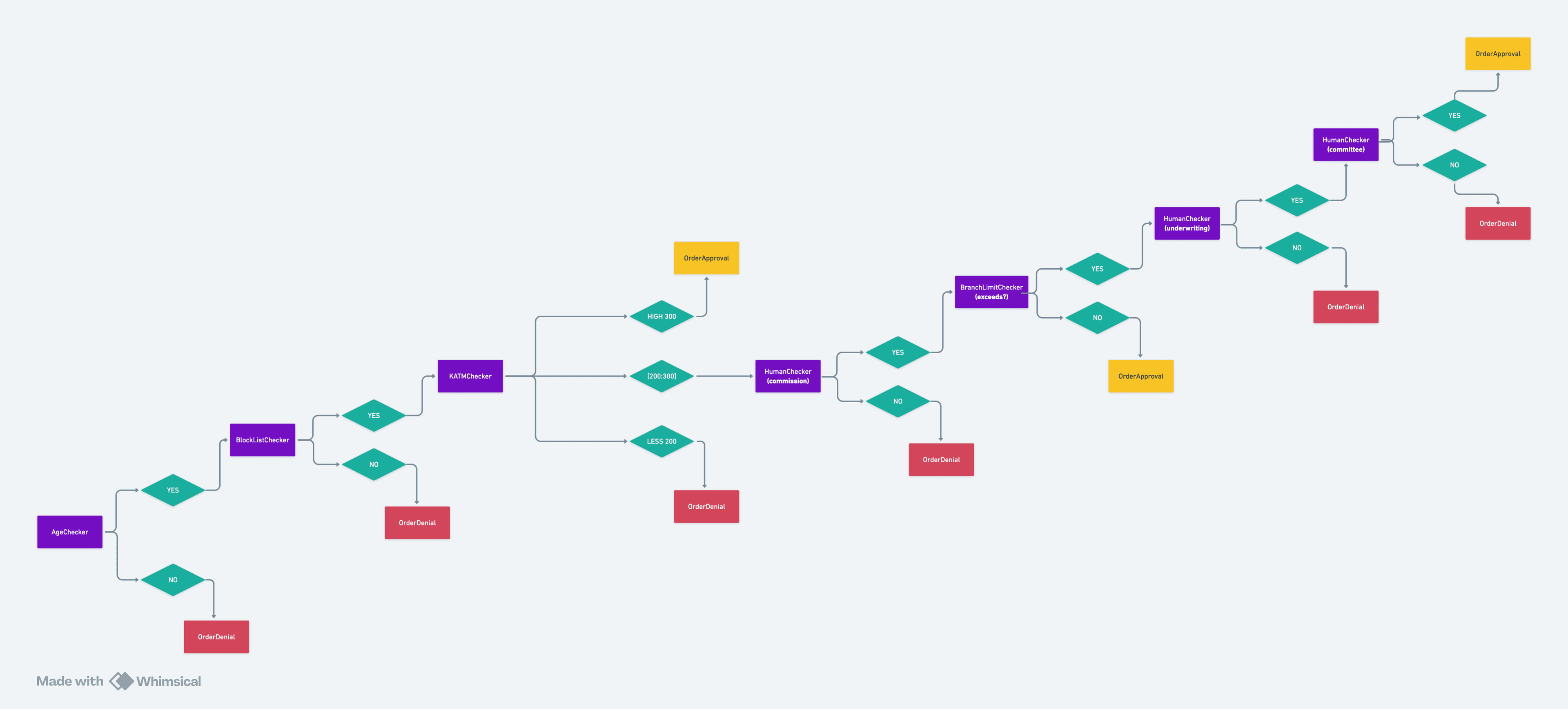
I sat down and tried to sketch what a typical loan order actually goes through. I started writing down each step as a small box, with the question it was responsible for answering. Is this customer on a blacklist? — yes or no. What is the customer's credit score? — a number, falling into one of several ranges. Does a commission officer in this role approve? — yes or no, with N votes required. Does an underwriter approve? — yes or no. Does a senior manager sign off? — yes or no. Then between each box I drew arrows for the possible answers, and each arrow pointed at the next box that should run depending on the answer. Some arrows pointed at the same destination. Some pointed at terminal "reject" and "approve" nodes. A few of the numeric boxes had three or four outgoing arrows, one per range.
When I stepped back from what I had drawn, the shape was a graph. Or more accurately, a directed graph. And the moment I named the shape, the structure of the solution wrote itself. The boxes were small reusable units. The arrows were separate from the boxes — they were a layer of routing on top. The boxes did not need to know which arrows were attached to them. The arrows did not need to know what the boxes did. A flow was a graph. A different product was a different graph over the same library of boxes. None of this required new code; it required tables.
I drew it cleaner in Whimsical and sent it to my CEO at 00:32 with a half-coherent explanation in our usual half-Uzbek, half-English working language — purple boxes are rules, each one has an output, the output can be boolean or numeric, and for numeric outputs we branch on ranges. He replied four minutes later with "ok, this works, we'll add a couple of situations later, for example deciding the next step based on a combination of several ranges rather than a single one." That generalization mattered and is what eventually gave us multi-input conditions. But the core was unblocked, and I started building. It was 00:32. I know because the message is still in my history, and I keep coming back to it the way you keep coming back to old photos of yourself. The text I sent my CEO that night, in our usual half-Uzbek half-English working language, said roughly this:
Assalomu aleykum Mirlaziz aka
sizdan decision making bo'yicha so'ramoqchi edim
shunaqa modelda ishlasa bo'ladimi? yana qanaqa case lar bo'lishi mumkin?
purpledagilarunit_rulebo'ladi, va har biri bajarilganidan keyin o'zinioutputi bo'lsa va unioutput_typei yokiboolean(true,falsebo'lishi mumkin masalan mijoz черный список da bormi yoqmi deganday), yokinumeric(masalan katm scoring)agar
output_typeson bo'ladigan bo'lsa unda harrangega qarab birunit_rulega bor deyishimiz mumkin.
Attached was a Whimsical board
He replied four minutes later. He is the kind of CEO who replies four minutes later at 00:36, which is one of the reasons I have stayed.)
Voaleykum assalom
ok hozir ko'raychi
Sizlar kechasi ijod qilaslarmi
Umuman olganda bo'ladi, keyin bir ikki boshqa vaziyatlarni qo'shamiz menimcha, Misol uchun bir nechta rangelar yig'indisiga qarab keyingi etapga o'tadigan bo'lishi mumkin.
"You folks create at night?" is the line I think about most often. He also said the model worked, that we would probably add a couple of cases later, like having the -next stage depend on a sum across several ranges instead of a single range. He was already generalizing the idea further than I had.
The second version
The schema settled into seven tables. They are easier to understand in the order they get used.
step_templates is the catalog of available step types. There is a row for human_checker, a row for scoring_checker, a row for blacklist_checker, a row for collateral_checker, a row for address_checker. Each row knows its result type, how many outgoing conditions it allows, and which configuration table holds its type-specific settings.
type StepTemplate struct {
Name string
Code string // "human_checker", "scoring_checker", ...
MinAllowedConditions int
MaxAllowedConditions int
ResultType string
ConfigTable *string // "human_checker_configs", ...
IsLast bool
IsBlocking bool
ConditionTemplates []*ConditionTemplate
}
This is the closet the flow-builder reaches into. You do not invent step types on the fly; you assemble flows out of the templates that already exist. Adding a new template is a backend change. Composing flows from existing ones is not.
steps is an instance of a template placed inside a specific flow. Each step refers back to its template, holds its own canvas Position for the drag-and-drop editor, and points to one row in whichever config table the template specifies.
type Step struct {
StepTemplateId uuid.UUID
Name string
ConditionsCount int
IsLast bool
IsBlocking bool
ResultType string
ConfigTable *string
Position json.RawMessage
HumanCheckerConfig *HumanCheckerConfig
ScoringCheckerConfig *ScoringCheckerConfig
BlacklistCheckerConfig *BlacklistCheckerConfig
CollateralCheckerConfig *CollateralCheckerConfig
AddressCheckerConfig *AddressCheckerConfig
Conditions []*Condition
}
The pointer-per-config-table thing is the polymorphism trick. A step is one of several kinds, and only one of those pointers is non-null at a time. Each config table is small and only holds what its step type actually needs. A human-checker step needs to know which role can vote, whether voting is restricted to the same branch as the order, and how many votes are required:
type HumanCheckerConfig struct {
RoleId uuid.UUID
BranchRestricted bool
RequiredNumberOfVotes int
}
A scoring step needs to know which external source to consult:
type ScoringCheckerConfig struct {
Source string
ReportType string
}
A blacklist step needs to know which list and what minimum score, if any, counts as "clean":
type BlacklistCheckerConfig struct {
Source string
MinScore *int
}
Each table exists because the corresponding step type genuinely needs different fields. Trying to merge them all into one row with a JSON blob is the kind of thing that feels clever for two weeks and is a regret for two years.
condition_templates lists the outgoing edges a step type is allowed to have. A human-checker template has two: approved, rejected. A scoring-checker template has one per range. The templates declare what edges are possible; the actual edges are instances.
conditions is the edges themselves. A condition row says "from this step, when the result equals this value, go to this next step."
type Condition struct {
ConditionTemplateId uuid.UUID
CurrentStepId uuid.UUID
NextStepId uuid.UUID
Name string
Result string
IsDefault bool
IsRemovable bool
Position json.RawMessage
}
The Result column carries the value that triggers the edge — "true" or "false" for boolean steps, a range identifier for numeric ones. IsDefault marks the fallback edge, which fires when no other condition matches. That guard exists because configurations get edited by humans, and "no edge matched" is the kind of failure mode you want to handle explicitly rather than crash through.
decision_making_systems is the named flow itself, and it is the smallest table in the whole design:
type DecisionMakingSystem struct {
Name string
IsFunctioning bool
EntryStepId uuid.UUID
EntryStep Step
FinancialProducts []*FinancialProduct `gorm:"many2many:..."`
}
A DMS is just an entry point — a pointer at the first step. The rest of the flow is discovered by walking the conditions out of that step, then their next steps, recursively. The many-to-many with financial_products is the part that makes this whole exercise pay back: one product can carry several DMS variants, and one DMS can power several products. Constructing a new flow for a new product is rows in tables, not lines in a switch statement.
The runtime is two more tables. order_workflow_states is the per-order pointer at the current step — order id, current step id, DMS id, and an is_completed flag. That is the entire moving part of the runtime.
order_step_results is the audit trail — one row per step the order has executed, in order, with the raw payload of whatever the step produced.
type OrderStepResult struct {
OrderId uuid.UUID
DecisionMakingSystemId uuid.UUID
StepId uuid.UUID
NextStepId *uuid.UUID
StepOrder int
Status string // "finished", "processing", "skipped"
ResultData string // raw bureau response, vote payload, score report
ExecutedAt time.Time
FinishedAt *time.Time
}
Two things are worth pointing at here. The first is ResultData. It stores the raw payload, not a summary. If a regulator or a customer or a lawyer asks what the system saw at that moment, the answer is one row away. The second is NextStepId. The runtime records not just what step ran, but which next step was chosen as a result. That makes the traversal replayable from the trail alone — useful when the flow has been edited since.
The execution loop, with the bookkeeping stripped out, is six steps. Load the current step and its config. Execute it — call out to the bureau, or open a voting record and wait for the configured number of votes, or whatever. Take the produced result and match it against the step's Conditions to pick a next step; fall back to the IsDefault edge if nothing matches. Write an OrderStepResult row capturing what just happened. Update the OrderWorkflowState pointer to the chosen next step. If the new step has IsLast = true, mark the workflow complete.
How a step actually advances
The execution loop, looks roughly like this. An order enters the system. It is bound to a financial product, which is associated with a decision-making system. The runtime picks the DMS, creates an OrderWorkflowState pointing at the DMS's EntryStep, and starts.
For each step:
- Load the step and its config.
- Execute the step. For an automated step that means calling out to whatever it integrates with: the credit bureau, the blacklist source, the scoring service. For a human step it means creating a voting record and waiting for the configured number of votes from people in the configured role.
- The step produces a result. The result is matched against the step's
Conditionsto pick a next step. Boolean steps have two conditions, one per value. Scoring steps have several, one per range. If nothing matches, theIsDefaultedge fires. - Write an
OrderStepResultrow capturing what just happened, including the raw payload and the chosenNextStepId. - Update
OrderWorkflowState.CurrentStepIdto the next step. - If the new step has
IsLast = true, mark the workflow complete.
A few things are worth pointing at here. Steps with IsBlocking = true halt the flow on rejection — they short-circuit to a terminal state instead of trying the next edge. Steps with IsBlocking = false are non-fatal; their failure routes to an alternative edge but does not kill the application. This is the difference between "you are on a blacklist, we stop" and "your scoring is low, but the flow continues to a manager-review step."
Human steps need a little more machinery than automated ones. The RequiredNumberOfVotes on HumanCheckerConfig means a step can be "approved by majority of two underwriters" or "requires unanimous approval from three commission members." The BranchRestricted flag scopes voting to people in the same branch as the order, which is the kind of constraint that you learn to support after the first time a branch manager in one city approves an application from a city he has never been to.
Why this shape ends up being the right one
The status-machine version solved one product at the cost of every additional one. Composing a new flow is inserting some steps, some conditions, and one DMS row — done through the drag-and-drop canvas, by a business user, with no engineering involvement. The same step types are reused across products with different configurations and different routing. Renaming a role does not break statuses, because there are no role-named statuses anymore.
A step does not know which DMS it belongs to. It does not know what step came before it. It does not know what step comes after — it only knows the conditions it owns, and the conditions own the pointers to next steps.
This is the property that pays back over time. Steps can be reused across flows without modification. Conditions can be edited without touching steps. Adding a new step type is a backend change to a single template plus its config table; adding a new flow that uses existing step types is a no-code change. The audit trail records exactly enough to reconstruct decisions even after the flow they ran under has been edited. None of these properties exist if you encode the workflow as statuses.
The fact that the engine is boring is the point. It loads a step, executes it, looks at the result, picks an edge, writes a row, advances the pointer. Six lines of logic, almost no branching. All the cleverness lives in the data — in the step templates, the condition templates, the per-product DMS configurations. That is where it should be. Engines should be dumb. Configurations should be rich. When you split a workflow system along that line, the engine stops needing changes after the first month, and everything that the business wants becomes a change to some rows in some tables.
What I took away from it
The thing I keep coming back to is that I did not solve this problem by being clever about code. I solved it by stepping back far enough from the problem that the shape became visible. As long as I was patching the switch statement, the answer was hidden in the details. The moment I stopped and drew the whole pipeline as boxes with arrows between them, the answer announced itself. It was a graph. Graphs have well-known shapes. The shape of the solution is implied by the shape of the problem, once you can see the whole problem at once.
I think most of my best engineering decisions have looked like this in retrospect. Spend more time than you think you need to understanding the problem. Resist the urge to start typing. Step back until you can see the whole thing in one frame, and almost always the right data structure is already there, waiting for you to recognize it. Graphs, trees, queues, ledgers, event streams — the world of available abstractions is small, and most problems map cleanly to one of them once you bother to look.
Learn the problem first. The solution usually comes by itself.